IEEE Spectrum talking about the possibility of robots being used for war:
http://spectrum.ieee.org/robotics/military-robots/autonomous-robots-in-the-fog-of-war
The entire idea of war being a Bad Thing aside, why do we keep blindly rushing toward Robot Apocalypse (yes, this is a theme for me)? It would be easier to handle if the experts were considering the possibilities, but they are not. Text from the article linked above shows that the author is entirely too dismissive of the possibilities.
<<
I've been working with robots for more than two decades, starting with underwater vehicles, then moving to air and ground vehicles, and most recently addressing collaborations among robots like those we demonstrated at the Robotics Rodeo. I can attest that while robots are definitely getting smarter, it is no easy task to make them so smart that they need no adult supervision. And call me a skeptic, but I doubt they'll be cloning themselves anytime soon.
>>
OK, I get it. You write for IEEE Spectrum, you are smart. However, sometimes the consequences are so bad that they need to be taken seriously even if they are unlikely (think expected value and black swans).
Also, there is all kinds of research being done right now on machines that can repair themselves (I blogged about this here back in January), so I think that this is something that we really should start taking more seriously.
Good grief.
Doesn't anybody read Philip K. Dick anymore? Second Variety should scare you enough to know better, and that was published in May 1953.

Friday, August 12, 2011
Thursday, August 11, 2011
Quine in Java
I was doing some reading on self replicating code (the bad kind) and stumbled onto this, which is very cool in an old school sort of way.
From Wikipedia:
A quine is a computer program which takes no input and produces a copy of its own source code as its only output. The standard terms for these programs in the computability theory and computer science literature are self-replicating programs, self-reproducing programs, and self-copying programs.
Here is a nice walk through of the thought process of creating a quine in Java:
http://blogs.adobe.com/charles/2011/01/my-adventure-writing-my-first-quine-in-java.html
The finished product of this blog looks like this (This was tested in eclipse. Note that the main function is only two lines. The wrapping is just so that it is easier to read on this blog):
public class Quine {
public static void main (String[] args) {
String s = "public class Quine {%3$c%4$cpublic static void main (String[] args) {%3$c%4$c%4$cString s = %2$c%1$s%2$c;%3$c%4$c%4$cSystem.out.printf(s, s, 34, 10, 9);%3$c%4$c}%3$c}";
System.out.printf(s, s, 34, 10, 9);
}
}
From Wikipedia:
A quine is a computer program which takes no input and produces a copy of its own source code as its only output. The standard terms for these programs in the computability theory and computer science literature are self-replicating programs, self-reproducing programs, and self-copying programs.
Here is a nice walk through of the thought process of creating a quine in Java:
http://blogs.adobe.com/charles/2011/01/my-adventure-writing-my-first-quine-in-java.html
The finished product of this blog looks like this (This was tested in eclipse. Note that the main function is only two lines. The wrapping is just so that it is easier to read on this blog):
public class Quine {
public static void main (String[] args) {
String s = "public class Quine {%3$c%4$cpublic static void main (String[] args) {%3$c%4$c%4$cString s = %2$c%1$s%2$c;%3$c%4$c%4$cSystem.out.printf(s, s, 34, 10, 9);%3$c%4$c}%3$c}";
System.out.printf(s, s, 34, 10, 9);
}
}
Tuesday, August 9, 2011
Entropy
ent is a very cool tool to quickly determine the entropy of a given file or stream.
Here is a quick demonstration:
The entropy of 'AAAAA':
 The entropy of '28183' (5 byte pseudorandom number generated by the rand program):
The entropy of '28183' (5 byte pseudorandom number generated by the rand program):

Now, let's consider these two outputs (much of the content below is from the ent man page):
Entropy (according to ent) is the information density of the contents of the file expressed as a number of bits per character. In the first example we see that 'AAAAA' is reported as having 0 entropy and that '28183' has 1.92. The takeaway here is that although '28183' is more dense than 'AAAAA', it is much less dense than one might expect.
The chi-square test is the most commonly used test for the randomness of data, and is extremely sensitive to errors in pseudorandom sequence generators. The chi-square distribution is calculated for the stream of bytes in the file and expressed as an absolute number and a percentage which indicates how frequently a truly random sequence would exceed the value calculated. We interpret the percentage as the degree to which the sequence tested is suspected of being non-random. If the percentage is greater than 99% or less than 1%, the sequence is almost certainly not random. If the percentage is between 99% and 95% or between 1% and 5%, the sequence is suspect.
Note: This test clearly shows that ent does not consider '28183' to be not very random at all.
This is simply the result of summing the all the bytes (bits if the -b option is specified) in the file and dividing by the file length. If the data are close to random, this should be about 127.5 (0.5 for -b option output). If the mean departs from this value, the values are consistently high or low.
Note: If a file is printable characters only (or some other subset of possible byte values), but still pseudorandom inside that set, then the value that represents the pseudorandom mean will be different. Additionally, it is unclear what general impact subsets of data have on the results reported by ent.
Each successive sequence of six bytes is used as 24 bit X and Y coordinates within a square. If the distance of the randomly-generated point is less than the radius of a circle inscribed within the square, the six-byte sequence is considered a "hit". The percentage of hits can be used to calculate the value of Pi. For very large streams (this approximation converges very slowly), the value will approach the correct value of Pi if the sequence is close to random. A 32768 byte file created by radioactive decay yielded: Monte Carlo value for Pi is 3.139648438 (error 0.06 percent).
This quantity measures the extent to which each byte in the file depends upon the previous byte. For random sequences, this value (which can be positive or negative) will, of course, be close to zero. A non-random byte stream such as a C program will yield a serial correlation coefficient on the order of 0.5. Wildly predictable data such as uncompressed bitmaps will exhibit serial correlation coefficients approaching 1.
Note: Interesting to see that '28183' ends up with a serial correlation somewhere between that of a C program and wildly predictable data.
Here is a quick demonstration:
The entropy of 'AAAAA':


Now, let's consider these two outputs (much of the content below is from the ent man page):
Entropy (according to ent) is the information density of the contents of the file expressed as a number of bits per character. In the first example we see that 'AAAAA' is reported as having 0 entropy and that '28183' has 1.92. The takeaway here is that although '28183' is more dense than 'AAAAA', it is much less dense than one might expect.
The chi-square test is the most commonly used test for the randomness of data, and is extremely sensitive to errors in pseudorandom sequence generators. The chi-square distribution is calculated for the stream of bytes in the file and expressed as an absolute number and a percentage which indicates how frequently a truly random sequence would exceed the value calculated. We interpret the percentage as the degree to which the sequence tested is suspected of being non-random. If the percentage is greater than 99% or less than 1%, the sequence is almost certainly not random. If the percentage is between 99% and 95% or between 1% and 5%, the sequence is suspect.
Note: This test clearly shows that ent does not consider '28183' to be not very random at all.
This is simply the result of summing the all the bytes (bits if the -b option is specified) in the file and dividing by the file length. If the data are close to random, this should be about 127.5 (0.5 for -b option output). If the mean departs from this value, the values are consistently high or low.
Note: If a file is printable characters only (or some other subset of possible byte values), but still pseudorandom inside that set, then the value that represents the pseudorandom mean will be different. Additionally, it is unclear what general impact subsets of data have on the results reported by ent.
Each successive sequence of six bytes is used as 24 bit X and Y coordinates within a square. If the distance of the randomly-generated point is less than the radius of a circle inscribed within the square, the six-byte sequence is considered a "hit". The percentage of hits can be used to calculate the value of Pi. For very large streams (this approximation converges very slowly), the value will approach the correct value of Pi if the sequence is close to random. A 32768 byte file created by radioactive decay yielded: Monte Carlo value for Pi is 3.139648438 (error 0.06 percent).
This quantity measures the extent to which each byte in the file depends upon the previous byte. For random sequences, this value (which can be positive or negative) will, of course, be close to zero. A non-random byte stream such as a C program will yield a serial correlation coefficient on the order of 0.5. Wildly predictable data such as uncompressed bitmaps will exhibit serial correlation coefficients approaching 1.
Note: Interesting to see that '28183' ends up with a serial correlation somewhere between that of a C program and wildly predictable data.
Thursday, April 14, 2011

Wednesday, April 13, 2011
Simple Trigonometric Functions with LabVIEW
The Unit Circle:
Needs no explanation.

This is a simple loop that utilizes the trig functions that are in the Mathematics -> Elementary and Special Functions -> Trigonometric Functions palette.

Three Screen Shots:
Here are a few screen shots from the front panel that show this simple VI in action.



Monday, April 11, 2011
Named Entity Extraction with Java
In February I posted on embedding weka in a java application based on content from this book by Mark Watson.
Recently I have been doing some work that requires some entity extraction, and I found another great tool and example set from the same book.
Here is some simple code that uses the classes provided:
package com.irodata.entity_extraction;
import com.markwatson.nlp.propernames.Names;
public class EntityExtraction {
public static void main(String[] args) {
Names names = new Names();
System.out.println("Hello World, Is New York a real place?");
System.out.println("New York: " + names.isPlaceName("New York"));
System.out.println("Hello World, Is Oz a real place?");
System.out.println("Oz: " + names.isPlaceName("Oz"));
}
}
The output is this:
Hello World, Is New York a real place?
New York: true
Hello World, Is Oz a real place?
Oz: false
I am going to be using and expansion of this to do some identification of places and proper names in some database text data to assist with analysis. If anything good and simple (and therefore appropriate for this blog) turns up I will be sure to share. For now, all I can say is that this is a good set of classes if you need to do some quick text work in Java.
I only had one small gotcha that I should reference for anyone that wants to try this out:
The text says this:
The “secret sauce” for identifying names and places in text is the data in the file test data/propername.ser – a serialized Java data file containing hash tables for human and place names.
When I first tried to build a test implementation, I kept getting this error:
java.io.FileNotFoundException: data/propername/propername.ser (No such file or directory)
After taking a look at the Names class, it appears that the location of the serialized data file was hard coded. It is possible that I am missing a simple Java convention, but the easiest solution for me was to copy the .ser file to the location that Names was looking for it (/data/propername/) and then import this file system resource into the eclipse project. It is possible that there is a better way to do this, if you know of one, please send me an email and I will update this post and give you credit. Otherwise, this worked. The resulting project looks like this:

Recently I have been doing some work that requires some entity extraction, and I found another great tool and example set from the same book.
Here is some simple code that uses the classes provided:
package com.irodata.entity_extraction;
import com.markwatson.nlp.propernames.Names;
public class EntityExtraction {
public static void main(String[] args) {
Names names = new Names();
System.out.println("Hello World, Is New York a real place?");
System.out.println("New York: " + names.isPlaceName("New York"));
System.out.println("Hello World, Is Oz a real place?");
System.out.println("Oz: " + names.isPlaceName("Oz"));
}
}
The output is this:
Hello World, Is New York a real place?
New York: true
Hello World, Is Oz a real place?
Oz: false
I am going to be using and expansion of this to do some identification of places and proper names in some database text data to assist with analysis. If anything good and simple (and therefore appropriate for this blog) turns up I will be sure to share. For now, all I can say is that this is a good set of classes if you need to do some quick text work in Java.
I only had one small gotcha that I should reference for anyone that wants to try this out:
The text says this:
The “secret sauce” for identifying names and places in text is the data in the file test data/propername.ser – a serialized Java data file containing hash tables for human and place names.
When I first tried to build a test implementation, I kept getting this error:
java.io.FileNotFoundException: data/propername/propername.ser (No such file or directory)
After taking a look at the Names class, it appears that the location of the serialized data file was hard coded. It is possible that I am missing a simple Java convention, but the easiest solution for me was to copy the .ser file to the location that Names was looking for it (/data/propername/) and then import this file system resource into the eclipse project. It is possible that there is a better way to do this, if you know of one, please send me an email and I will update this post and give you credit. Otherwise, this worked. The resulting project looks like this:

Thursday, April 7, 2011
Historical Machine Learning Definition - Arthur Samuel
Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
Came across this while doing some general work. I enjoy the history of AI, so many things that we take for granted now were unknown only 50 years ago. There are more modern (and more formal) definitions, but this one has an elegance to it.
Checkers is now solved (thanks Chinook), but that does not make the original 1959 results any less cool. As a matter of fact, I think that it might make the original results even more cool.
Came across this while doing some general work. I enjoy the history of AI, so many things that we take for granted now were unknown only 50 years ago. There are more modern (and more formal) definitions, but this one has an elegance to it.
Checkers is now solved (thanks Chinook), but that does not make the original 1959 results any less cool. As a matter of fact, I think that it might make the original results even more cool.
Wednesday, April 6, 2011
LEGO MINDSTORMS NXT - Shift Register
Here is another cool example from the LabVIEW examples that ship with the NXT module:
Description:
This example is for the LEGO MINDSTORMS NXT. The program uses a while loop and shift register to add 1 to the value of the previous iteration, the value is displayed for one second resulting in the NXT counting by seconds.
 Nice and simple, but very cool.
Nice and simple, but very cool.
Description:
This example is for the LEGO MINDSTORMS NXT. The program uses a while loop and shift register to add 1 to the value of the previous iteration, the value is displayed for one second resulting in the NXT counting by seconds.

Saturday, April 2, 2011
The Cathedral and the Bazaar
The entire essay is a bit much for a blog post, here is a link to the whole thing:
http://www.redhat.com/support/wpapers/community/cathedral/whitepaper_cathedral.html
Here is just a bit from the beginning:
Certainly not I. By the time Linux swam onto my radar screen in early 1993, I had already been involved in Unix and free-software development for ten years. I was one of the first GNU contributors in the mid-1980s. I had released a good deal of free software onto the net, developing or co-developing several programs (nethack, Emacs VC and GUD modes, xlife, and others) that are still in wide use today. I thought I knew how it was done.
Linux overturned much of what I thought I knew. I had been preaching the Unix gospel of small tools, rapid prototyping and evolutionary programming for years. But I also believed there was a certain critical complexity above which a more centralized, a priori approach was required. I believed that the most important software (operating systems and really large tools like Emacs) needed to be built like cathedrals, carefully crafted by individual wizards or small bands of mages working in splendid isolation, with no beta to be released before its time.
Linus Torvalds's style of development - release early and often, delegate everything you can, be open to the point of promiscuity - came as a surprise. No quiet, reverent cathedral-building here -- rather, the Linux community seemed to resemble a great babbling bazaar of differing agendas and approaches (aptly symbolized by the Linux archive sites, who'd take submissions from anyone) out of which a coherent and stable system could seemingly emerge only by a succession of miracles.
The fact that this bazaar style seemed to work, and work well, came as a distinct shock. As I learned my way around, I worked hard not just at individual projects, but also at trying to understand why the Linux world not only didn't fly apart in confusion but seemed to go from strength to strength at a speed barely imaginable to cathedral-builders.
By mid-1996 I thought I was beginning to understand. Chance handed me a perfect way to test my theory, in the form of a free-software project which I could consciously try to run in the bazaar style. So I did -- and it was a significant success.
In the rest of this article, I'll tell the story of that project, and I'll use it to propose some aphorisms about effective free-software development. Not all of these are things I first learned in the Linux world, but we'll see how the Linux world gives them particular point. If I'm correct, they'll help you understand exactly what it is that makes the Linux community such a fountain of good software -- and help you become more productive yourself.
http://www.redhat.com/support/wpapers/community/cathedral/whitepaper_cathedral.html
Here is just a bit from the beginning:
1. The Cathedral and the Bazaar
Linux is subversive. Who would have thought even five years ago that a world-class operating system could coalesce as if by magic out of part-time hacking by several thousand developers scattered all over the planet, connected only by the tenuous strands of the Internet?Certainly not I. By the time Linux swam onto my radar screen in early 1993, I had already been involved in Unix and free-software development for ten years. I was one of the first GNU contributors in the mid-1980s. I had released a good deal of free software onto the net, developing or co-developing several programs (nethack, Emacs VC and GUD modes, xlife, and others) that are still in wide use today. I thought I knew how it was done.
Linux overturned much of what I thought I knew. I had been preaching the Unix gospel of small tools, rapid prototyping and evolutionary programming for years. But I also believed there was a certain critical complexity above which a more centralized, a priori approach was required. I believed that the most important software (operating systems and really large tools like Emacs) needed to be built like cathedrals, carefully crafted by individual wizards or small bands of mages working in splendid isolation, with no beta to be released before its time.
Linus Torvalds's style of development - release early and often, delegate everything you can, be open to the point of promiscuity - came as a surprise. No quiet, reverent cathedral-building here -- rather, the Linux community seemed to resemble a great babbling bazaar of differing agendas and approaches (aptly symbolized by the Linux archive sites, who'd take submissions from anyone) out of which a coherent and stable system could seemingly emerge only by a succession of miracles.
The fact that this bazaar style seemed to work, and work well, came as a distinct shock. As I learned my way around, I worked hard not just at individual projects, but also at trying to understand why the Linux world not only didn't fly apart in confusion but seemed to go from strength to strength at a speed barely imaginable to cathedral-builders.
By mid-1996 I thought I was beginning to understand. Chance handed me a perfect way to test my theory, in the form of a free-software project which I could consciously try to run in the bazaar style. So I did -- and it was a significant success.
In the rest of this article, I'll tell the story of that project, and I'll use it to propose some aphorisms about effective free-software development. Not all of these are things I first learned in the Linux world, but we'll see how the Linux world gives them particular point. If I'm correct, they'll help you understand exactly what it is that makes the Linux community such a fountain of good software -- and help you become more productive yourself.
Monday, March 28, 2011
Autonomous Robotic Vehicles
Interesting stuff, I have to say that the 'mind control' tag line is a bit misleading. Maybe this is more like 'hands free driving'... ;-)
Robots Podcast #74 (25Mar2011): Mind Control

Raul Rojas, who was also featured in Robots Podcast Episode 64: Autonomous Vehicles, returns to discuss the work being done at AutoNOMOS Labs to develop an interface that allows a person to direct a largely autonomous vehicle with their thoughts. He is followed by Geoff Mackellar, CTO and Research Manager of Emotiv, developers of the EPOC neuroheadset used by AutoNOMOS Labs. Finally, the web page for this episode links to a TED talk given by Tan Le of Emotiv.
Thursday, March 24, 2011
LabVIEW RESTful Web Services
Here are some notes about another LabVIEW example that I thought was really good:
Weather Station Monitor Example
1) Deploy weather data.lvlib
2) Run Update Weather Data VI
3) Open the Tools>>Options dialog. Click on the Configure Web Application Server button and ensure that the Application Web Server is enabled.
4) Click OK and save changes.
5) Build and Deploy the Weather Monitor RESTful Web Service from the Build Specifications item in the project.
6) Open a web browser on the local PC and browse to the following URL: http://localhost:8080/weather/station/2507987
NOTE: The default port that the NI Application Web Server listens on is 8080. If this port has been modified, the above URLs need to change to use that port.
I hope to see more work in the next few years solving problems with distributed robots that are Internet connected, here is how easy it was to make this example work:
1. OK.
2. This VI is generated the simulated weather data (obviously this gets really cool if there are sensor networks deployed that are reporting real data).

3. OK. Small note, I had to install Silverlight to get the web configuration tool.
Here is the first screen:

Here is the web configuration tool:

4. OK. - not too much to say on this one.
5. OK - not too much to say on this one, either.
6. OK.
Here is what the page looks like:

Here is what the source of the page looks like:
<html><body><h1>URL: /weather/</h1><h2>Output Terminals</h2><table border=1.0><tr><th>Terminal Name</th><th>Terminal Value</th></tr><tr><td>Pressure</td><td>1004.651939</td></tr><tr><td>Temperature</td><td>27.198859</td></tr><tr><td>Wind Speed</td><td>2.933509</td></tr><tr><td>Station ID</td><td>2507987</td></tr><tr><td>Wind Direction</td><td>257.230547</td></tr></table></body></html>
So, the example is pretty easy. Building an application like this from scratch with real sensors would obviously not be quite as simple as the few clinks that it took to make this work. However, it seems clear that some really powerful applications can be built with this technology. All I need to do now is learn more LabVIEW!
Weather Station Monitor Example
1) Deploy weather data.lvlib
2) Run Update Weather Data VI
3) Open the Tools>>Options dialog. Click on the Configure Web Application Server button and ensure that the Application Web Server is enabled.
4) Click OK and save changes.
5) Build and Deploy the Weather Monitor RESTful Web Service from the Build Specifications item in the project.
6) Open a web browser on the local PC and browse to the following URL: http://localhost:8080/weather/station/2507987
NOTE: The default port that the NI Application Web Server listens on is 8080. If this port has been modified, the above URLs need to change to use that port.
I hope to see more work in the next few years solving problems with distributed robots that are Internet connected, here is how easy it was to make this example work:
1. OK.
2. This VI is generated the simulated weather data (obviously this gets really cool if there are sensor networks deployed that are reporting real data).

3. OK. Small note, I had to install Silverlight to get the web configuration tool.
Here is the first screen:

Here is the web configuration tool:

4. OK. - not too much to say on this one.
5. OK - not too much to say on this one, either.
6. OK.
Here is what the page looks like:

Here is what the source of the page looks like:
<html><body><h1>URL: /weather/</h1><h2>Output Terminals</h2><table border=1.0><tr><th>Terminal Name</th><th>Terminal Value</th></tr><tr><td>Pressure</td><td>1004.651939</td></tr><tr><td>Temperature</td><td>27.198859</td></tr><tr><td>Wind Speed</td><td>2.933509</td></tr><tr><td>Station ID</td><td>2507987</td></tr><tr><td>Wind Direction</td><td>257.230547</td></tr></table></body></html>
So, the example is pretty easy. Building an application like this from scratch with real sensors would obviously not be quite as simple as the few clinks that it took to make this work. However, it seems clear that some really powerful applications can be built with this technology. All I need to do now is learn more LabVIEW!
Wednesday, March 23, 2011
Radiation Detector Robot Deployed in Fukushima
These robots look awesome, and are doing a very important job. The full story here: http://www.pcworld.com/article/222947/radiation_detector_robot_deployed_in_fukushima.html

Saturday, March 19, 2011
Publications by Googlers in Artificial Intelligence and Data Mining
There is a ton here that is very interesting stuff:
http://research.google.com/pubs/ArtificialIntelligenceandDataMining.html
Additionally, there is a category for machine learning here:
http://research.google.com/pubs/MachineLearning.html
These appear to be the two categories most interesting to me, but there are many others as well.
On a side note, technically speaking I think that it is correct to consider Data Mining and Machine Learning both as sub disciplines of Artificial Intelligence.
This is supported by the following capabilities as described from Artificial Intelligence: A Modern Approach 2nd Edition (I have not yet updated to the 3rd Edition):
I guess that Google has divided up the way that they did based on the volume of research and the groupings that made the most sense to them. Not really a big deal, but I find it interesting. Also, note that the disciplines identified above are focused on an AI approach of 'acting humanly'. This is one of the four generally acknowledged approaches of modelling AI (possibly for consideration at some later time):
http://research.google.com/pubs/ArtificialIntelligenceandDataMining.html
Additionally, there is a category for machine learning here:
http://research.google.com/pubs/MachineLearning.html
These appear to be the two categories most interesting to me, but there are many others as well.
On a side note, technically speaking I think that it is correct to consider Data Mining and Machine Learning both as sub disciplines of Artificial Intelligence.
This is supported by the following capabilities as described from Artificial Intelligence: A Modern Approach 2nd Edition (I have not yet updated to the 3rd Edition):
- natural language processing
- knowledge representation
- automated reasoning
- machine learning
- computer vision
- robotics
I guess that Google has divided up the way that they did based on the volume of research and the groupings that made the most sense to them. Not really a big deal, but I find it interesting. Also, note that the disciplines identified above are focused on an AI approach of 'acting humanly'. This is one of the four generally acknowledged approaches of modelling AI (possibly for consideration at some later time):
- acting humanly
- thinking humanly
- thinking rationally
- acting rationally
Wednesday, March 16, 2011
LabVIEW NXT Module Examples
OK, so I know that this is pretty simple... but I have been working with this module off and on for a while and have managed to overlook these:
From the main screen, select 'find examples' then expand 'toolkits and modules'... voila! Tons of great examples to get you going with your NXT.
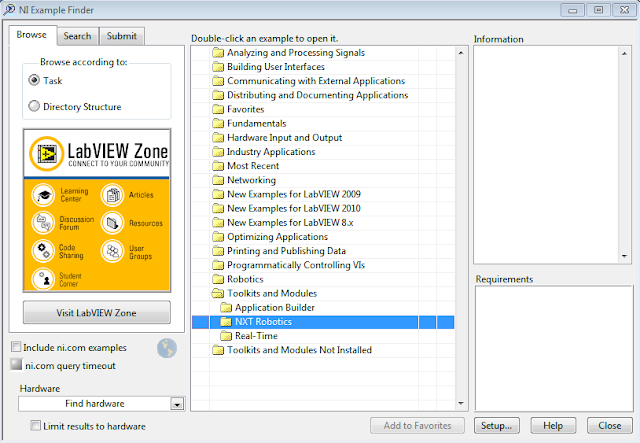
I will be picking a few of my favorites and showing demos of them in future posts.
From the main screen, select 'find examples' then expand 'toolkits and modules'... voila! Tons of great examples to get you going with your NXT.
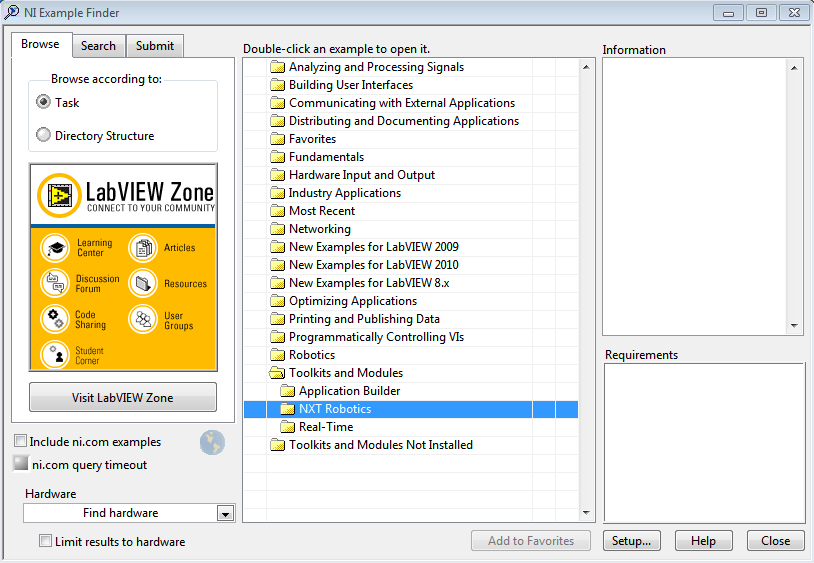
I will be picking a few of my favorites and showing demos of them in future posts.
Tuesday, March 15, 2011
Japanese Quake and Tsunami Ultimate Test for Rescue Robots
Here is another good article about rescue robots in Japan:
http://robots.net/article/3122.html

As observed on RobotLand, shortly after the earthquake and tsunami in Japan,
http://robots.net/article/3122.html
As observed on RobotLand, shortly after the earthquake and tsunami in Japan,
Rescue robots help relief efforts in the aftermath of earthquakes and other disasters by navigating through wreckage that is too dangerous for people to enter and by gathering information on missing persons and the surrounding conditions. Small unmanned marine vehicles, both surface (boats) and ROVs (underwater), can be of assistance in inspecting bridges for underwater damage or debris posed to crash into the substructure and damage the bridge. Recent years have seen rapid advances in the development of these robots, and Japan is a global leader in the field.Between the advanced state of robotics in Japan, the extent of the damage, and the likelihood that the wreckage continues to conceal living persons, the current situation presents an unprecedented, pressing opportunity to put the whole range of rescue robots to the test. Ironically, as reported by the Center for Robot-Assisted Search and Rescue,
the leading researchers from Japan in rescue roboticswere in the U.S. for the CRASAR-organized JST-RESPONDR exercise and workshop, although they returned to Japan immediately. Robin Murphy of CRASAR has been mentioned here repeatedly in connection with rescue robots. POPSCI.com was also quick to publish an article about (primarily Japanese) rescue robots, including photos, and PHYSORG.com has video.
Japan: Robotic snakes to the rescue
Thanks to Rob for sharing this link from here:
http://www.boingboing.net
A summary of the content below. Hopefully the technology can help save people.

CNET: "Rescue robots are making their way to parts of Japan affected by the massive earthquake and tsunamis that devastated coastal areas Friday and in the days following, leaving nearly 6,000 people dead or missing. A team from Tohoku University led by Satoshi Tadokoro is apparently en route to Sendai with a snakelike robot that can wriggle into debris to hunt for people."
http://www.boingboing.net
A summary of the content below. Hopefully the technology can help save people.
CNET: "Rescue robots are making their way to parts of Japan affected by the massive earthquake and tsunamis that devastated coastal areas Friday and in the days following, leaving nearly 6,000 people dead or missing. A team from Tohoku University led by Satoshi Tadokoro is apparently en route to Sendai with a snakelike robot that can wriggle into debris to hunt for people."
Matrix Fundamentals in LabVIEW
Here is another good example:
The following example shows the fundamental behavior and functionality of the matrix data type. While the test is running, you can change the matrix inputs or select built-in or user-defined numeric operations. Change the operation mode between matrix and array versions of the operations to see the difference in results.
The front panel:


The following example shows the fundamental behavior and functionality of the matrix data type. While the test is running, you can change the matrix inputs or select built-in or user-defined numeric operations. Change the operation mode between matrix and array versions of the operations to see the difference in results.
The front panel:

The block diagram:
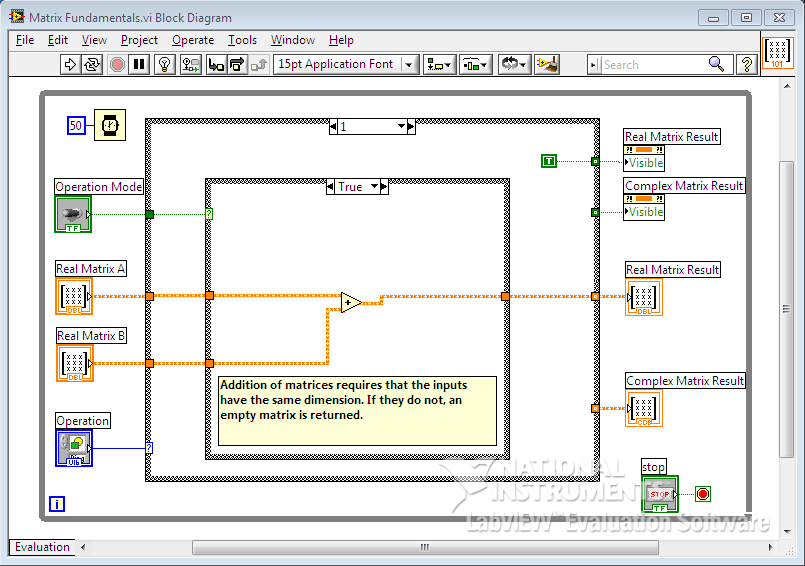
Friday, March 11, 2011
Simple Command-Line Lucene Demo
The following demo is based on the demo located here:
http://lucene.apache.org/java/3_0_3/demo.html
First, create three one line text files to index and search. The image below shows the files and contents that I used for this demo.



http://lucene.apache.org/java/3_0_3/demo.html
First, create three one line text files to index and search. The image below shows the files and contents that I used for this demo.

Now index the files by typing 'java org.apache.lucene.demo.IndexFiles' followed by the files that you want to index. In the image below you see that I indexed the directory ./testDocs/:

Finally, here are some example searches against the index that show one, two, or no results based the query that was issued. To issue a query type 'java org.apache.lucene.demo.SearchFiles' and then enter what you want to search for.

Wednesday, March 9, 2011
Lucene
http://lucene.apache.org/java/docs/index.html
"Apache Lucene(TM) is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform."
I am beginning to consider software agents as in play for deeper discussion, and suspect that discussion of text mining is relevant to the general intent of this blog.
Look for some more posts in coming days focused on this topic.
"Apache Lucene(TM) is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform."
I am beginning to consider software agents as in play for deeper discussion, and suspect that discussion of text mining is relevant to the general intent of this blog.
Look for some more posts in coming days focused on this topic.
Monday, March 7, 2011
Lego Mindstorms NXT 2.0 Bonus Models
http://mindstorms.lego.com/en-us/support/buildinginstructions/8547/Bonus%20Model%201.aspx
Nice designs to try out one of these days, but right now I am still playing with my derivative of the explorer bot.
Nice designs to try out one of these days, but right now I am still playing with my derivative of the explorer bot.
Thursday, March 3, 2011
LabVIEW Robotics Module - Single Control Loop
Here is another example from the LabVIEW Robotics Module. I like this one for a few reasons:
This Single Control Loop example is useful for robots that do relatively simple, repetitive algorithms. Insert code for acquiring and processing sensor data and controlling the robot inside this Timed Loop. The Functions>>Robotics palette contains useful robotics-related VIs and functions.
This Timed Loop controls timing and is configured to run at 10 Hz. However, all processing must execute fast enough to keep up with this loop rate. The Previous Iteration Finished Late? Boolean returns TRUE if the contents of the loop does not finish fast enough for the current configuration of the Timed Loop. If this occurs, consider slowing the loop rate or optimizing the contents of the loop.
If you do not need a fixed loop rate and want this loop to run as fast as possible, right-click the loop border and select Replace with While Loop.
>>
The Block Diagram:

The Project Explorer:

- It is relatively simple
- It generates and processes simulated data (so you can play with it without hardware)
- It has worked cleanly and easily the first time
This Single Control Loop example is useful for robots that do relatively simple, repetitive algorithms. Insert code for acquiring and processing sensor data and controlling the robot inside this Timed Loop. The Functions>>Robotics palette contains useful robotics-related VIs and functions.
This Timed Loop controls timing and is configured to run at 10 Hz. However, all processing must execute fast enough to keep up with this loop rate. The Previous Iteration Finished Late? Boolean returns TRUE if the contents of the loop does not finish fast enough for the current configuration of the Timed Loop. If this occurs, consider slowing the loop rate or optimizing the contents of the loop.
If you do not need a fixed loop rate and want this loop to run as fast as possible, right-click the loop border and select Replace with While Loop.
>>
The Block Diagram:

The Project Explorer:

Tuesday, March 1, 2011
The Rise of Worse is Better
In many ways it is hard to believe that it took this long for a post about (or at least related to) Lisp. Last month, I started off with a post about The Manifesto for Agile Software Development. Not sure if this is going to be a pattern, but I thought that this month I would start off with another software engineering type of a post.
The following is taken from here:
http://dreamsongs.com/WIB.html
The Rise of Worse is Better
I and just about every designer of Common Lisp and CLOS has had extreme exposure to the MIT/Stanford style of design. The essence of this style can be captured by the phrase the right thing. To such a designer it is important to get all of the following characteristics right:
The worse-is-better philosophy is only slightly different:
However, I believe that worse-is-better, even in its strawman form, has better survival characteristics than the-right-thing, and that the New Jersey approach when used for software is a better approach than the MIT approach.
The following is taken from here:
http://dreamsongs.com/WIB.html
The Rise of Worse is Better
I and just about every designer of Common Lisp and CLOS has had extreme exposure to the MIT/Stanford style of design. The essence of this style can be captured by the phrase the right thing. To such a designer it is important to get all of the following characteristics right:
- Simplicity -- the design must be simple, both in implementation and interface. It is more important for the interface to be simple than the implementation.
- Correctness -- the design must be correct in all observable aspects. Incorrectness is simply not allowed.
- Consistency -- the design must not be inconsistent. A design is allowed to be slightly less simple and less complete to avoid inconsistency. Consistency is as important as correctness.
- Completeness -- the design must cover as many important situations as is practical. All reasonably expected cases must be covered. Simplicity is not allowed to overly reduce completeness.
The worse-is-better philosophy is only slightly different:
- Simplicity -- the design must be simple, both in implementation and interface. It is more important for the implementation to be simple than the interface. Simplicity is the most important consideration in a design.
- Correctness -- the design must be correct in all observable aspects. It is slightly better to be simple than correct.
- Consistency -- the design must not be overly inconsistent. Consistency can be sacrificed for simplicity in some cases, but it is better to drop those parts of the design that deal with less common circumstances than to introduce either implementational complexity or inconsistency.
- Completeness -- the design must cover as many important situations as is practical. All reasonably expected cases should be covered. Completeness can be sacrificed in favor of any other quality. In fact, completeness must sacrificed whenever implementation simplicity is jeopardized. Consistency can be sacrificed to achieve completeness if simplicity is retained; especially worthless is consistency of interface.
However, I believe that worse-is-better, even in its strawman form, has better survival characteristics than the-right-thing, and that the New Jersey approach when used for software is a better approach than the MIT approach.
Monday, February 28, 2011
Meka Robotics M1 Mobile Manipulator
Meka M1 Mobile Manipulator vimeo from Meka Robotics on Vimeo.
This video is from here:
http://spectrum.ieee.org/automaton/robotics/humanoids/meka-robotics-announces-mobile-manipulator-with-kinect-and-ros
Cool looking robot.
Wednesday, February 23, 2011
RoboEarth
http://www.roboearth.org/
Cool stuff. A little scary. They have a number of documents about their work that appear interesting.
Cool stuff. A little scary. They have a number of documents about their work that appear interesting.
Monday, February 21, 2011
The Meaning of Symbols in Problem Solving
The following is taken from here: http://robots.open.ac.uk/minicourse/
Another great problem in robotics is getting them to understand language. This is very important in problem-solving. For example, the four cards below have a letter on one side and a number on the other. If a card has a vowel (a, e, i, o, u) on one side then it has an even number on the other. Which cards do you have to turn over to see if this is true? Think about your answer, then point to a card to turn it over.
Now consider the following cards where the rule is ‘every time I go to Paris I go by plane’. Which cards have to be turned over to test this? Again, think about your answer before turning the card over.
The answer to the first question is that you have to turn over the E to see if it has an even number on the back and you have to turn over the 7 to check that it does not have a vowel on the back. In an experiment, only 12% of people got this second part right (did you?).
The answer to the second question is much easier. Of course you have to turn over the Paris card to check that it has the word plane on the back, but now it’s much more obvious that you have to turn over the train card to make sure it does not have Paris on the back. In the experiment mentioned above, 60% of people got the second part right.
These problems are logically the same, so the experimenters drew the conclusion that the meaning of the symbols is an important part of problem solving. Since robots have very poor language capabilities, their ability to use this kind of reasoning is very limited.
Another great problem in robotics is getting them to understand language. This is very important in problem-solving. For example, the four cards below have a letter on one side and a number on the other. If a card has a vowel (a, e, i, o, u) on one side then it has an even number on the other. Which cards do you have to turn over to see if this is true? Think about your answer, then point to a card to turn it over.
 |  |  |  |
 |  |  |  |
The answer to the second question is much easier. Of course you have to turn over the Paris card to check that it has the word plane on the back, but now it’s much more obvious that you have to turn over the train card to make sure it does not have Paris on the back. In the experiment mentioned above, 60% of people got the second part right.
These problems are logically the same, so the experimenters drew the conclusion that the meaning of the symbols is an important part of problem solving. Since robots have very poor language capabilities, their ability to use this kind of reasoning is very limited.
Thursday, February 17, 2011
Using the Finite State Machine Design Pattern in LabVIEW to Implement the xkcd 90s Flowchart
There are a number of really great flowcharts from xkcd, I chose this one to implement in LabVIEW as an example of using the Finite State Machine Design Pattern:

Implementation Notes:
First, create a new VI from template and select the Standard State Machine:

This gets you started with a template VI:

Then implement the flowchart as a Finite State Machine. Note that the end VI is a bit hard to visualize based on the nature of the Case structure, here are some screen shots that show each of the cases followed by some screen shots of the front panel at different states.
First initialize and give the user a message that the test is starting.
 Then ask the user if it is the 90s. If yes continue to 'State 2', if no go to state 'Stop'.
Then ask the user if it is the 90s. If yes continue to 'State 2', if no go to state 'Stop'.
 If it is the 90s the program gets to 'State 2'. Now ask the user to choose between MC Hammer (MCH) and Vanilla Ice (ICE). Then return the string associated with the user choice and advance to the 'Stop' state.
If it is the 90s the program gets to 'State 2'. Now ask the user to choose between MC Hammer (MCH) and Vanilla Ice (ICE). Then return the string associated with the user choice and advance to the 'Stop' state.
 Stop the program.
Stop the program.

Here are example screen shots of the program:





Implementation Notes:
- I am assuming an implied program stop after 'hammertime' and 'listen'.
- The 'Stop' after 'No' is a stop of the program.
- The 'Stop' after 'Yes' is a sub string of the program output (surrounded by matching parenthesis in order to avoid tension).
- I have added a decision after the data flow 'Yes'->'Stop' to select either 'MCH' (MC Hammer) or 'ICE' (Vanilla Ice) which then determines which string the program returns.
First, create a new VI from template and select the Standard State Machine:
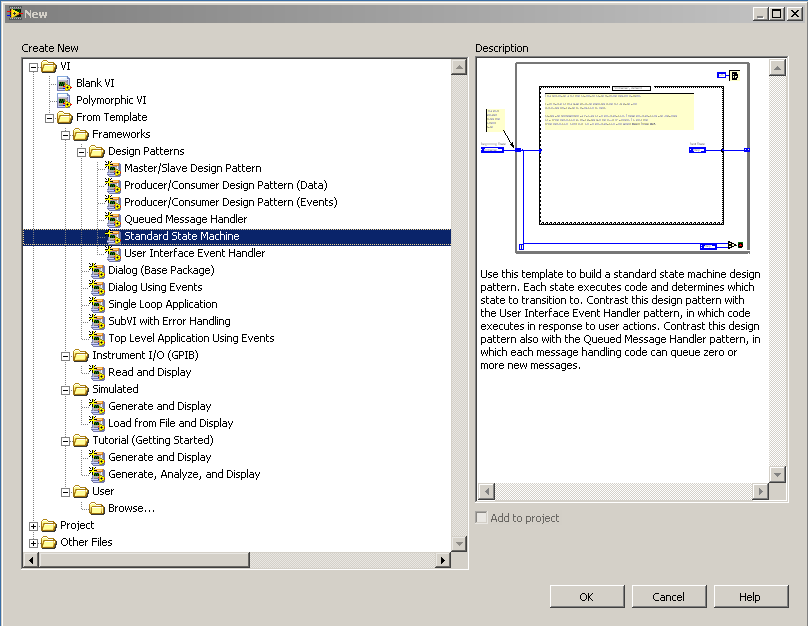
This gets you started with a template VI:

Then implement the flowchart as a Finite State Machine. Note that the end VI is a bit hard to visualize based on the nature of the Case structure, here are some screen shots that show each of the cases followed by some screen shots of the front panel at different states.
First initialize and give the user a message that the test is starting.




Here are example screen shots of the program:
Tuesday, February 15, 2011
Sense, Think, Act for Unmanned Robotic System
http://zone.ni.com/wv/app/doc/p/id/wv-1646
"Sense. Think. Act." Is a traditional model in robotics, this is a nice explanation about its implementation in LabVIEW.
"Sense. Think. Act." Is a traditional model in robotics, this is a nice explanation about its implementation in LabVIEW.
Friday, February 11, 2011
Embedding Weka in a Java Application
Discovered a book, Practical Artificial Intelligence Programming in Java, from here:
http://www.markwatson.com/. Lots of good stuff in this, but the bit that really got my attention was how easy and clean the explanation was for how to embed Weka into a Java application.
If you are not familiar with Weka, I highly recommend that you go here to learn more about it: http://www.cs.waikato.ac.nz/ml/weka/
In summary, the steps to use and modify the example were as follows:
Here is a screen shot of adding weka.jar to the project:

Here is the Java code (modified only slightly from the example referenced above):
import weka.classifiers.meta.FilteredClassifier;
import weka.classifiers.trees.ADTree;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.filters.unsupervised.attribute.Remove;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class main {
public static void main(String[] args) throws Exception {
Instances training_data = new Instances(new BufferedReader(
new FileReader("test_data/weather.arff")));
training_data.setClassIndex(training_data.numAttributes() - 1);
Instances testing_data = new Instances(new BufferedReader(
new FileReader("test_data/weather.arff")));
testing_data.setClassIndex(training_data.numAttributes() - 1);
String summary = training_data.toSummaryString();
int number_samples = training_data.numInstances();
int number_attributes_per_sample = training_data.numAttributes();
System.out.println("Number of attributes in model = "
+ number_attributes_per_sample);
System.out.println("Number of samples = " + number_samples);
System.out.println("Summary: " + summary);
System.out.println();
// J48 j48 = new J48();
ADTree adt = new ADTree();
Remove rm = new Remove();
rm.setAttributeIndices("1");
FilteredClassifier fc = new FilteredClassifier();
fc.setFilter(rm);
fc.setClassifier(adt);
fc.buildClassifier(training_data);
for (int i = 0; i < testing_data.numInstances(); i++) {
double pred = fc.classifyInstance(testing_data.instance(i));
System.out.print("given value: "
+ testing_data.classAttribute().value(
(int) testing_data.instance(i).classValue()));
System.out.println(". predicted value: "
+ testing_data.classAttribute().value((int) pred));
}
}
}
Here are the results:

I used the ADTree classifier on the weather.arff demo data. This is a very simple example, and I hope in the future to go into more detail about how machine learning tools like Weka can be used as part of an agent based programming approach.
http://www.markwatson.com/. Lots of good stuff in this, but the bit that really got my attention was how easy and clean the explanation was for how to embed Weka into a Java application.
If you are not familiar with Weka, I highly recommend that you go here to learn more about it: http://www.cs.waikato.ac.nz/ml/weka/
In summary, the steps to use and modify the example were as follows:
- Create a project
- Add weka.jar to the build path
- Copy and tweak the code from the example
- Examine results
Here is a screen shot of adding weka.jar to the project:

Here is the Java code (modified only slightly from the example referenced above):
import weka.classifiers.meta.FilteredClassifier;
import weka.classifiers.trees.ADTree;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.filters.unsupervised.attribute.Remove;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class main {
public static void main(String[] args) throws Exception {
Instances training_data = new Instances(new BufferedReader(
new FileReader("test_data/weather.arff")));
training_data.setClassIndex(training_data.numAttributes() - 1);
Instances testing_data = new Instances(new BufferedReader(
new FileReader("test_data/weather.arff")));
testing_data.setClassIndex(training_data.numAttributes() - 1);
String summary = training_data.toSummaryString();
int number_samples = training_data.numInstances();
int number_attributes_per_sample = training_data.numAttributes();
System.out.println("Number of attributes in model = "
+ number_attributes_per_sample);
System.out.println("Number of samples = " + number_samples);
System.out.println("Summary: " + summary);
System.out.println();
// J48 j48 = new J48();
ADTree adt = new ADTree();
Remove rm = new Remove();
rm.setAttributeIndices("1");
FilteredClassifier fc = new FilteredClassifier();
fc.setFilter(rm);
fc.setClassifier(adt);
fc.buildClassifier(training_data);
for (int i = 0; i < testing_data.numInstances(); i++) {
double pred = fc.classifyInstance(testing_data.instance(i));
System.out.print("given value: "
+ testing_data.classAttribute().value(
(int) testing_data.instance(i).classValue()));
System.out.println(". predicted value: "
+ testing_data.classAttribute().value((int) pred));
}
}
}
Here are the results:

I used the ADTree classifier on the weather.arff demo data. This is a very simple example, and I hope in the future to go into more detail about how machine learning tools like Weka can be used as part of an agent based programming approach.
Wednesday, February 9, 2011
Monday, February 7, 2011
LabVIEW Robotics Module - Rotation Matrix Example
I was able to download the evaluation of the LabVIEW 2010 Robotics Module (unfortunately not available for Mac at the time of this writing) and wrote this quick VI to demonstrate using the Angle Vector to Rotation Matrix VI and the Rotation Matrix to Angle Vector VI.

This simple VI takes an angle, in radians, by which the rotation occurs and a vector specifying the x, y, and z coordinates of the point around which to rotate.
The front panel for this VI allows the user to double check the Homogenous Transforms by using the output of one transform as the input of the other as shown below:

The rotation matrix is very important to a number of robotics operations. There is a ton that could be said about this as it relates to kinematics and the representation and manipulation of an end effector, but for now I am happy to make the VI work.
So far I have had a few issues with the examples that have come with the Robotics Module and in terms of a product for business use I have some concerns. It also appears that because I am using the evaluation version some of the implementations that I am most interested in looking at are protected. Even with these limitations, the LabVIEW 2010 Robotics Module has been very interesting to look at.
This simple VI takes an angle, in radians, by which the rotation occurs and a vector specifying the x, y, and z coordinates of the point around which to rotate.
The front panel for this VI allows the user to double check the Homogenous Transforms by using the output of one transform as the input of the other as shown below:

The rotation matrix is very important to a number of robotics operations. There is a ton that could be said about this as it relates to kinematics and the representation and manipulation of an end effector, but for now I am happy to make the VI work.
So far I have had a few issues with the examples that have come with the Robotics Module and in terms of a product for business use I have some concerns. It also appears that because I am using the evaluation version some of the implementations that I am most interested in looking at are protected. Even with these limitations, the LabVIEW 2010 Robotics Module has been very interesting to look at.
Friday, February 4, 2011
Automatically Clean Up LabVIEW Block Diagrams
http://zone.ni.com/devzone/cda/tut/p/id/7386
This is a good one. I especially like the explanation of how the clean up tool can be configured. I am interested to work with this and see if there might be a mechanism for custom style guidelines to be created and implemented for a team of developers (this is common in text based programming teams).

This is a good one. I especially like the explanation of how the clean up tool can be configured. I am interested to work with this and see if there might be a mechanism for custom style guidelines to be created and implemented for a team of developers (this is common in text based programming teams).

Subscribe to:
Posts (Atom)